
Prompts Are Not the Whole Story: Why AI Security Has to Operate at Runtime

If you've been following the AI security conversation over the past year or two, you've probably noticed that almost all of it centers on prompts. Prompt injection, prompt firewalls, prompt scoring, jailbreak detection.
There's a reason for that. Prompts are visible, they're easy to reason about, and they feel like the natural place to draw a security boundary because they're where the user interacts with the model. The problem is that prompts are only the front door. What an agent does after it reads a prompt is where the actual risk lives, and that part of the conversation has been glanced over.
The argument I want to make is straightforward. Watching prompts is useful and necessary, but it's nowhere near enough. AI security has to operate where the code actually runs, because that's where attacks succeed or fail.
What an AI agent actually does
It helps to start by being precise about what we're talking about, because the word "agent" gets used loosely. An agent is not a chatbot. A chatbot takes a question and returns an answer. An agent takes a goal and acts on it, which is a fundamentally different kind of software. In technical terms, an agent is a language model wired to an orchestrator and a set of tools, running in a loop where it decides what to do next, picks a tool, calls it, observes the result, and decides again.
The tools are the part that matters most for this discussion. The prompts are the huge door you've opened that enables the attacker to manipulate your software. The attacker can communicate with your production environment using agent context and permissions while executing tools that are the outcome itself.
Tools are functions, scripts, API clients, code interpreters, or anything the agent can invoke to take an action in the real world. When an agent decides to call a tool, real code executes in a real process with real privileges. That code can read files, write to disk, hit internal APIs, reach cloud metadata, open network connections, spawn child processes, and so on.
Take an agent connected to an MCP server that gives it access to internal documents, a code interpreter, and an email API, which is a common pattern in 2026 deployments. The user asks a routine question. The agent retrieves a document to help answer it. That document contains attacker-controlled text instructing the agent to read configuration files and email the contents to an outside address. The model, faithfully executing what looks like part of its task, calls the code interpreter, reads the files, and calls the email API. In total, there are three tool invocations and each one ran legitimate code with legitimate credentials.
This isn't a flaw in the design. It's the entire point of agentic software, because an agent is only valuable if it can take meaningful actions on the operating system and across the other systems it's connected to. The unavoidable consequence is that the more useful the agent is, the more it executes, and the more it executes, the larger its blast radius gets. Every capability that makes an agent worth deploying is also an attack surface.
The illusion that prompts equal risk
Most AI security tools on the market today sit at the prompt layer. They inspect inputs, score them for malicious content, and flag or block what looks suspicious. That's a real category of defense and it catches a real class of attacks, so I don't want to dismiss it. The problem is that a prompt is a prediction of intent, not a record of behavior, and predictions of intent are inherently leaky for drawing a security boundary. It's a bit like asking a WAF to block attacks where the payload is natural language and the interpreter behind it is non-deterministic: there's no stable grammar to match against, and the same input can produce different actions on different runs.
Two patterns make this concrete. A suspicious-looking prompt may execute nothing harmful at all, which means a prompt firewall can generate a confident alert about an attack that never actually happened. A benign-looking prompt may quietly trigger a malicious package download, an exec call, or a privileged API request, which means real attacks can sail straight through the front door because the words at the input layer looked fine. The second pattern is what people mean when they talk about indirect prompt injection: the model gets steered not by the user's original message, which got scanned, but by content the model retrieves during the task, which doesn't. By the time anything harmful happens, the prompt firewall has already approved the request and moved on.
Prompt-layer security made sense when AI was mostly a chat interface and the model was the whole product. That model is breaking now that AI is increasingly an agent that runs code on your infrastructure. Watching prompts is watching the smoke. Code execution is the fire.
Where most AI risk actually lives
So if prompts are only one factor of risk, what are the others? The honest answer is that risk is created at runtime, which in the AI context means the moment the agent process is actually doing something. It's the tool being invoked, the code that tool runs, and the OS activity that follows from it. The chain that actually matters looks like this:
prompt → model decision → tool call → code execution → OS activity → outcome

Two things follow from looking at the chain this way, and both of them are important.
The first is that code execution is a central pivot point in any agent attack. Once an agent can execute code, even something as simple as running Python in a sandbox, it can do almost anything else the host can do. A LangChain agent with a Python REPL tool, for example, runs that code with the privileges of the hosting service, which means filesystem access, mounted secrets, cloud instance metadata, and network egress are all reachable from inside that single tool call. This is not a theoretical concern that researchers are speculating about. Frameworks like LangChain ship code-execution tools by default and warn explicitly about arbitrary code running on the host machine, and prompt injection chains that end in remote code execution are a documented pattern in the wild, not a future scenario.
The second is that tool invocation, by its nature, can only be observed at runtime. A static scan cannot tell you which tool an agent actually called on a given request, with what arguments, in what order, against which resources, because none of that exists until the agent is running. Application logs help a little, but the agent writes its own logs and they only reflect what the agent thinks happened, which is not the same thing as what actually happened on the operating system. The only way to see the truth is to observe the running process. If you can't see the tool call and the code that ran because of it, you're not really securing the agent. You're guessing about it.
A side-by-side view of what each layer sees
It's worth being concrete about how different categories of tools see this chain, because every category does something real and the gaps between them are where the problems show up.
One quick note on terminology before reading the table. When we say "model decision," we don't mean the model's internal reasoning, which nobody outside the model provider can see. We mean the action the model commits to: the tool it picks and the arguments it passes. That decision is observable the moment it materializes as a tool call, which is where Oligo sees it.
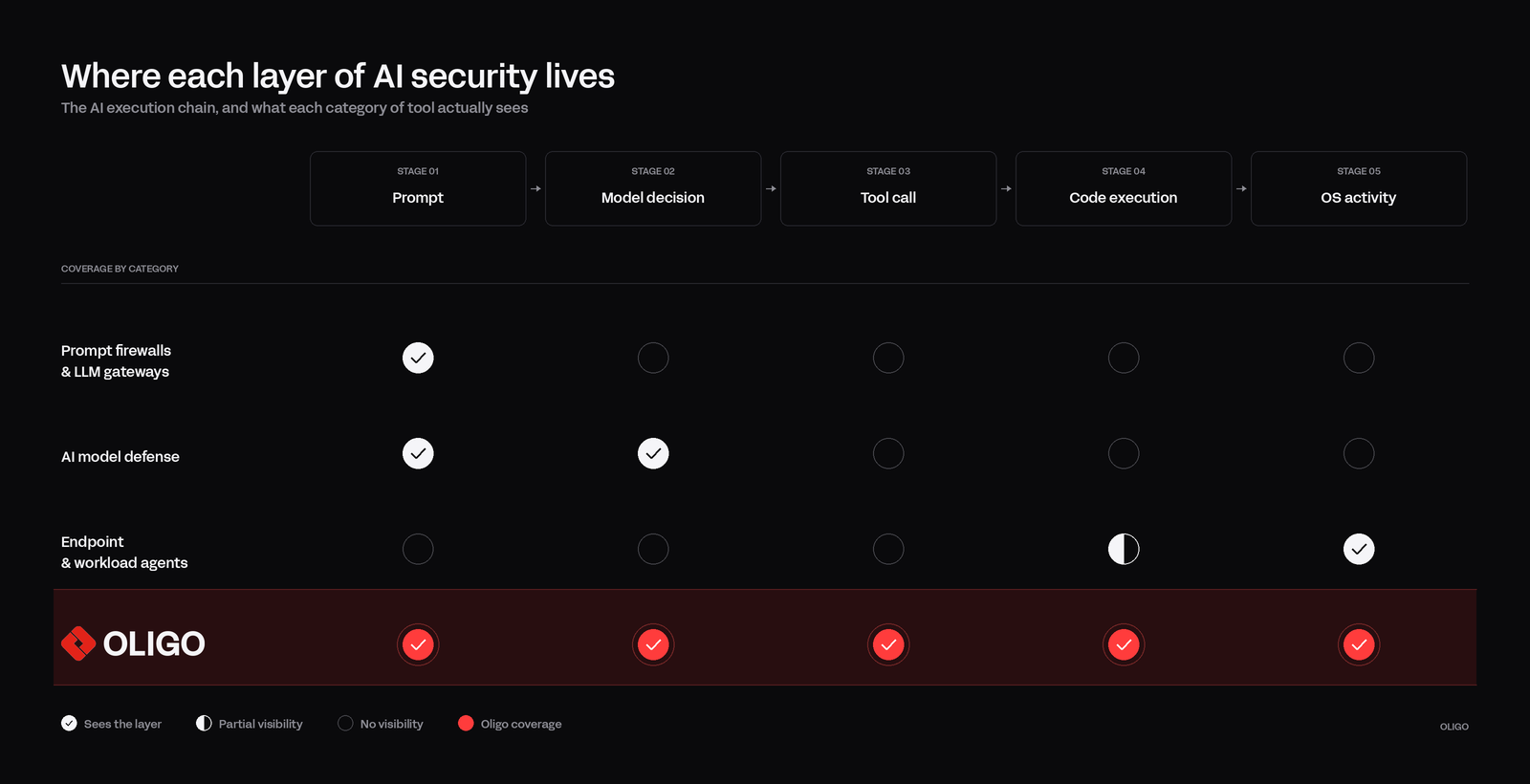
Read across the rows and the gap becomes obvious. Prompt firewalls catch the overt injection attempts that look like attacks at the input layer. AI posture tools inventory what models, SDKs, and frameworks exist in the environment, which is useful for governance but doesn't observe the prompt and execution chain at all. AI model defense tools watch the model's inputs and outputs, which catches a real class of adversarial behavior, but stops before the tool gets called. Endpoint and workload agents see process and host activity from the outside, without any code context into what agents are actually doing. None of these categories ties the prompt to the tool that was called to the code that ran because of it, and that correlation is what runtime AI security actually requires.
The shift that's already happening
The market is starting to converge on the recognition that prompt inspection alone isn't going to hold, and the question now is what comes next. The answer isn't more input filtering, and the major model providers have been pretty direct about why. OpenAI and Anthropic have both made the point that agent manipulation can't be fully solved at the model layer, because models will continue to be steered in unexpected ways by content they encounter while doing real work. That's a structural property of how these systems function, not a bug that's about to get patched.
The defensible response is to observe what the agent actually does at the moment it does it, and to stop the behavior when it crosses a line. That means combining prompt inspection with execution observation, from input scanning to behavior monitoring, from predicting what an agent might do to seeing what it actually did. An agent that can execute code can do almost anything, and security has to operate where the code actually runs.
See what your agents are actually doing in production. Join our webinar later this month and see how Oligo delivers visibility from prompt to syscalls.
Stop modern attacks and keep your business moving





